People have often commented on how strange it is that Google has two OSes in Android and ChromeOS. Some talk about how it is doing the “Microsoft thing” by setting up an internal competition, and Google is big enough to do that kind of thing.
There were many who saw that “the Web will eventually win”, but as Android’s numbers get larger and larger, others are pondering things. Is the timing off? Has Android gotten too large to let itself lose to Chrome OS? Is the app ecosystem for Chrome OS not up to snuff with Android (let alone iOS)?
If Google pulled the plug on Chrome OS it would feel like a bad day for the Web. Chrome OS needs push the entire Web forward. Chrome is adding features to WebKit and Chromium at a very healthy rate, and the Chrome OS pieces make sure that features that flush out the Web to rival native environments come along. Without the Chrome OS project being part of the whole Chrome ecosystem, that may not quite be the case.
There are some projects that Google should go long on, and some that should be experiments. You could argue that Wave was an experiment that didn’t warrant continued evolution, but Chrome OS should. It moves the Web forward.
The Web has a lot of huge benefits, but it is still hard at it going up against iOS, Android, and others. We need a lot of investment to give the Web the SDK that developers are striving for, so they can deliver compelling experiences. We aren’t there yet.
With Google and Chrome OS, HP and webOS, and even a lot of other players (e.g. RIM and its Web support, Nokia and its, etc etc) we are seeing a healthy double-take on taking the Web forward and making the next big platform truly multi-vendor.
“Merging” with Android is interesting. Android’s web stack has gotten better recently, but it is very much lacking, and you could argue that getting the Chrome/WebKit talent and putting it on the Android stack could do a lot for the Web, and maybe bring the Web up to be a true Android platform. That could be a good thing, but would it ever truly be a first class citizen compared to the “Java but not really Java” stack?
I truly hope that Google double downs on Chrome and Chrome OS, and gives it time to have the Web come along for the next ride as more than the ghetto that some would like to see it become.
I mentioned Vapour, the Mozilla Open Web App Store. I didn’t know that it wasn’t released yet (even though the code was out there).
Well, now it has been released with the post on an Open Web App Ecosystem that has a prototype and technical documentation with it.
This is a huge deal, and I am jazzed that Mozilla is getting into the game here. The Web needs to give developers as many opportunities to monetize as possible, and needs to help consumers find the best possible content.
First we have the philosophy on what an Open Web App even is:
Are built using HTML, CSS and JavaScript.
Can be “installed” to a dashboard within your mobile or desktop Web browser, or to your native OS desktop or mobile home screen.
Work in all modern Web browsers, while enabling each browser to compete on app presentation, organization and management user interfaces.
Support paid apps by means of an authorization model that uses existing identity systems like OpenID.
Support portable purchases: An app purchased for one browser works in other browsers, and across multiple desktop and mobile platforms without repurchase.
Can request access to one or more advanced and/or privacy-sensitive capabilities that they would like access to (like geolocation) which the system will mediate, giving the user the ability to opt-in to them if desired.
Can be distributed by developers directly to users without any gatekeeper, and distributed through multiple stores, allowing stores to compete on customer service, price, policies, app discoverability, ratings, reviews and other attributes.
Can receive notifications from the cloud.
Support deep search across apps: Apps can implement an interface that enables the app container (generally the Web browser) to provide the user with a cross-app search experience that links deeply into any app that can satisfy the search.
There are some interesting elements in there, such as calling out notification support as a first class required feature.
Then we get to the brass tacks. The tech behind this. I quickly peaked at the manifest and was happy to see that it looks very similar to Chrome (and the webOS appinfo.json). I would love to see us all get in a room and try to come up with some subset of JSON that we can agree on.
I also enjoyed seeing:
Permissions: The thought around permissions and what it means to be an app.
Verification: How do we actually make things like “buy on Chrome, use on Firefox” working? How do we allow distributed systems for payment and all of the services that tend to be silo’d right no?
Great to see the word now fully out, and now we have the concept we can join Mozilla in helping to define how this all works, and how it can be useful. It is so very hard to compete with a unified system, and to make it happen takes real work and collaboration. What do you think?
I remember growing up walking past grocers and butchers, and having my Mum stop by to get fresh meat and veg on a daily basis. I look back fondly on that experience, as I contrast it to the later years of mega-stores. When I came back to England for a year stint, a few years back, I was shocked to see that Tesco didn’t just sell food anymore, but had branched out to credit cards and gas and lots of crazy things.
The local stores have been wedged out.
On Sunday, I took my kids to the farmers market (happens most weekends), which is what had me think back to the local stores from my own childhood.
Fast forward a few months, and we see a new project in a very early stage. Vapour (github repo has been removed) is the Mozilla Labs project that is “An experiment around an Open Web App Store.” I am excited about the project for two reasons:
Mozilla is uniquely positioned to deliver a marketplace that focuses on very different values than other companies
I see check-ins from two amazing people: Michael Hanson (who did the amazing work around “people”) and Lloyd Hilaiel (who recently joined Mozilla. I tried to hire him there years back, and he waiting for me to leave. Hmm :)
Also, I got to hang with the OpenAppMkt chaps at the Node Knockout get together last night. They have only just begun, and think they will do some great things.
I evangelize the farmers market. I market it. I try to sell it.
I think of the Mozilla effort as the farmers market of app stores. The values are different. It isn’t just about values though, it will be about product. Many folk go to the farmers market because the goods are better. It is incredibly hard to compete with the likes of Walmart. They squeeze the market and force their vendors in a race to the bottom around price. This is the trick that Walmart can play. They can hold on to: “Look, we are giving everyone cheap goods!” It doesn’t matter what they do with China, or how they treat workers. Surely it is all for good if we can get things cheap right?
The same is happening with the major app stores. These platforms sell consumers with a fantastic user experience and looking after their users. No viruses. No “bad stuff”. Clean. They offer true value, but there is always a cost.
The app markets are as strong as wal-mart. I am excited to see new endeavors that change the game and deliver great user value, while also giving great freedom.
Dimitris Vardoulakis has created a Doctor. A Doctor for JavaScript that does static analysis on your code to tease out the type information and more.
This is fantastic work, and is something that we were dreaming of when we first planned Bespin. What if the cloud was constantly analyzing your code and returning type metadata back to the clients that were accessing it? That metadata can be used for tasks such as code completion and documentation.
Give it a try to see what comes out the other end. The samples show you a lot, such as polymorphism:
function id(x){return x;}
id(42);
id('hello, doctor!');// returns
id :function(<number | string>) → <number | string>
and prototypes:
function Rectangle(w, h){this.w= w;this.h= h;}
Rectangle.prototype.area=function(){returnthis.w*this.h;};var a =(new Rectangle(2,3)).area();// returns
Rectangle :function(number, number) → any
area :function() → number
and exceptions:
function findLargest(a){if(a.length===0)thrownew Error('empty array');var max = a[0];for(var i =1, l = a.length; i < l; i++)if(a[i]> max)
max = a[i];return max;}function foo(){var a =[1,2,3];try{return findLargest(a);}catch(e){return e.message;}}
foo();// returns
findLargest :function(Array[number]) → number
foo :function() → <number | string>
and callbacks:
function call(f, x){return f(x);}function add1(n){return n +1;}function truncate(s){return s.substring(0, s.length-1);}var n = call(add1,41);var s = call(truncate,'abcd');// returns
call :function(<function(number) → number |function(string) → string>,<number | string>) → <number | string>
add1 :function(number) → number
truncate :function(string) → string
Mike Shaver talked about the great work that is coming in JS land right now for Moz…. and it is showing. Can’t wait to see both Firefox and Bespin gain from this all!
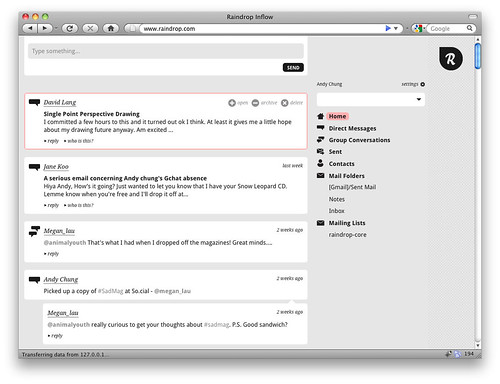
Raindrop was so exciting to me, as it allows me to take ownership of how I handle communications.
Gmail is fantastic in that I have been able to extend my experience via Greasemonkey and the Labs tweaks, but it isn’t really open to me.
With Raindrop, you not only get to scrape out some flexibility in the client, but you get to do it the entire stack down. You can write code that changes BOTH frontend and backend. Have you ever wanted to do more than simple filters? Write handlers for particular content in an email? Help you mashup your email in any way? Raindrop will give you that.
It is early days of course. Mozilla is known for getting something out there early so the community can influence it, so jump in.
I am also excited to see that you can hack on things right int he client via an embedded Bespin. Awesome, I can’t wait to see what happens next guys!
Ben, myself, and the Bespin team are obviously excited about what we are doing. Giving Web developers a tool platform that is self-hackable and is also built-in-social has us up at night dreaming. We need help though! One way of course is joining the community, but if you fancy hacking on this problem full time, we have a new job opening for a Mozilla Labs engineer.
If you have a passion for open source, working with community, at an open company and want to spend some time making the editor sexy, please apply.
If you are interested in other positions, Mozilla is hiring across the board. I can tell you from experience that it is very difference working for a mission based organization, and if you think you would like that, come check us out.
Do you sometimes feel like the browser is a black box? We are building richer and richer applications on the Web platform and this means that developers are running up against new issues to debug and test.
We feel like it is a great time to develop new tools that afford you the ability to look into the runtime to hopefully help you find a bug, or allow you to keep your application as responsive as possible.
Today we want to start a conversation about some of our thinking, with the hope that you will join in.
We have been taking a hard look at the tools landscape, and here is a presentation that gives you an idea of our thinking:
We will be posting more of our thoughts, but as you can hear, our vision for these tools is that they:
Are able to run out-of-process. We view out of process tools as the preferred way to observe the runtime because it enables us to somewhat ignore the Heisenberg uncertainty principle. If we are profiler the browser, having to deal with NOT profiling the profiler code can be painful. Also, we want to be able to use the same tools on devices. I would much rather point my desktop tool to a Fennec device, compared to trying to use the tool on the phone itself! This leads us too…
Enable cross browser experiences: Our lab doesn’t have the resources to develop deep integrations with multiple browsers, but we very much want to enable that. Since we are running out-of-process, we can document the communication API and many hosts can then be wired up.
The first experiment in this vein is a stand-alone memory tool prototype that lets you poke around in the JavaScript heap. What objects are there? How many of them are there? Any dangling references due to closures or event listeners?
To kick this off we worked with awesome Mozilla colleagues such as David Barron and Atul Varma which enabled us to spike down to the bare metal of the browser.
We ended up with an architecture for the tool that contains these components:
Firefox Add-on
A special Firefox add-on installs a binary component that gives us access to the low level JavaScript heap. This gives us a simple API with methods that allow you to enable profiling, get the root objects in the heap, and get detailed information on the objects themselves.
Firefox Memory Server
The current consumer of the core API is a min server. Once activated, the browser freezes and your only option to interact with it is via this server. It exposes a simple socket API with URLs mapping to the high level APIs. For example, you can access /gc-roots to get the root object ids. Or you can ask for details on an object via /objects/XXX where XXX is the object id you are inspecting. When you are done, you access /quit and the browser is unfrozen.
All of these APIs support JSONP which is how we get the data back into our main application.
The main application itself is a simple Web application that can be run in any browser (not just Firefox!) After you have installed the Firefox Add-on, and turned on profiling via the Memory Server, you can visit the tool. Currently, after you connect, the tool gets a dump of the root object for the first tab in the browser (not including the memory server tab). You will see the meta data associated with the object, and you can click on any of the data elements that have their own memory id (memory locations are integers with 9 digits). This tree view lets you poke around the heap.
If you want to aggregate the data, you can click on the “2. Dump Heap” button, which goes through the entire heap (which can be big!) and aggregates all of the objects for you. If you see a massive number of objects of a particular type, this could be a flag!
Enough talk, lets see it briefly in action:
The tool is very early stage and changing constantly. However, it is all out in the open. You can grab the open source pieces:
As is always the case with Mozilla, and Mozilla Labs, we want to get ideas out into the community as soon as possible. This tool is very much alpha, and the goal of getting it out in the wild is to start a conversation about tools like these.
What tools in this area would help your job as a Web developer? We are all ears, and would like to share our dev tools mailing list / group as a good area to share ideas.
What about Firebug? This particular tool freezes the browser, and since Firebug is in-process right now, it wasn’t a great fit. However, we very much want to take this kind of work and get it into Firebug at some stage. We just aren’t at that stage yet!
On our side, we will be engaging with the Mozillans who truly grok the JavaScript (and entire browser) internals to see what interesting data we can expose to developers. We have found that the Firefox team has already added a lot of the infrastructure there, and now the task is to work out what will be useful, and how can we best report it.
We have plenty of ideas too. A wish list could contain:
Short term clean up (fix the backend code that interfaces with the heap, abstract out the service into a Jetpack, and make sure we are using the correct APIs, and get these APIs added where appropriate)
We want to visually add the graph to the object dump, so you can really understand what you are looking at. It will probably look something like this:
We have wired up Bespin, and we will suck out the source code from functions and showing that inline to the tool itself. There is much more to do though, and we want to find out what you need.
More profiling info: break up buckets of memory (images, js, DOM, etc)
Great way to see who is reference whom (memory leak detection)
Garbage Collection: When and how long are collections occuring?
Granular filtered profiling: Profile this event and measure every event-of-interest from the start of navigation to the present e.g. DNS & TCP connections, page header parsing, resource fetching, DOM parsing, reflow, etc.
Web Worker thread monitoring
Have a profiling mode that gives you data without having to freaze the heap, and only when you need to do a deep dive do we get to that.
We have learned a lot as we created this prototype. Atul is going to write up his experience, and we will continue to talk in the open about how we take this prototype and your ideas to the next level with browsers.
Update
Atul has posted on his experience with SpiderMonkey and how the JS Runtime works. Nice in depth stuff. He also created PyMonkey “a Python C extension module to expose the Mozilla SpiderMonkey engine to Python.” which is crazy cool.
It was cool to see the second release of Jetpack with its storage, slidebars, and time travel from the .future().
I quickly hacked up a trivial slidebar that lets me mouse to see the source of the current tab, and click on it to have it stick around. All in a few lines of code that use the new future API, slideBar, and tabs:
When I first saw the top sites feature that Safari took to the extreme (look wise) I jumped up and down shouting about how I wouldn’t want this feature at all. I am the king of about:blank.
Why would I want to waste time for this new tab page to come up when I normally want to just go somewhere (often the “where” is in my clipboard).
Well, after a week of using Safari 4 I realised that I hadn’t switched it off, and it hadn’t bothered me even though I knew it would bother me!
The reason is of course due to the speed. The reason I always hated setting my “home page” to anything but about:blank was because of the time it would take to grab and render the page. I have never been a “put iGoogle there!” kinda guy. Too slow, and not in my flow at all.
I don’t find that I often USE the top sites to get somewhere because the way I get to common sites is that I put them into tabs and I use APPLE-# (where # is a number of the tab) to get there. Thus, the whole notion of top sites doesn’t make much sense for me. The history area has been used once or twice and coverflow is waaaay too much here.
Now, Aza and company have been doing fun work with what this would look like in Firefox. It is a lot more subtle, especially the latest visual update. I love the subtle things such as knowing that I often go to my clipboard to having an action right there.
I also have really enjoyed how this has all been done as a plugin itself, and the process has happened very much in the open. Imagine if you could talk to the Apple engineers and help them do the best job they could for Safari? You can’t. With us, you can.
Also, this being Firefox, you can tweak the hell out of this puppy by greasemonkeying the page, setting the page to your own beast, or writing your own plugin to do something really fancy (like being able to tie into the same places database to do cool things).
You may think that you will hate these new pages, but as long as they load up just as fast as an empty page (perceived to be) you may find that, like me, you don’t actually care at all.
I was excited to hear about the Canvas 3D effort that Mozilla, Google, and Khronos are engaged in (and others can too of course).
Khronos is the group being OpenGL, and thus a good set of folks to be involved in the Canvas 3D approach that is in the mould of “OpenGL ES like for the Web” in that it is a low level API that others can build on top of. Others have played with higher level “Games” APIs, or virtual worlds, and this is not the same. It is a primitive that will enable people to do interesting things that sit on top.
I noted Ryan Stewart (friend and great chap) weighing in:
So it’s unfortunate to see that even the browser vendors have given up on moving the open web forward through standards. Whether it’s the WHATWG versus the W3C or the trials and tribulations of actually implementing HTML5, things are very broken and everyone is moving on regardless. I don’t blame any of them, but it doesn’t seem like it’s good for web developers.
I already talked about how many of the leaps on the Web haven’t started in the W3C (and rarely start inside standards orgs first) and rather come out in browser implementations that are then shared. Think XMLHttpRequest. Think Canvas itself from Apple! Do something well, see people use it and get excited about it, and then get multiple implementations and standards. Everyone wins.
John’s wording is interesting:
“But Mozilla’s proposal relies upon further proprietary extensions to the experimental CANVAS tag”
“And you’d lose the moral fulsomeness of the ‘Web Standards for The Open Web!’ pitch when focusing on your own proprietary alternatives to existing standards.”
Look at how browsers have done some things recently. Take some of the new CSS work that Apple started out. When the Mozilla community liked what they saw, and had developers demanding, they went and implemented it too. When you see WebKit and Gecko doing this kind of work it is particularly Open because the projects are open source and you can check them out (well, if you are allowed ;) How great is that, to iterate nicely in the open…. and then when ready we can drive into the standards bodies.
Back to the Canvas 3D work. Having Mozilla, Google, and Khronos work on this in the open seems pretty darn good to me. This won’t be hidden behind a proprietary binary that no-one can see. There will be some work in marrying the world of OpenGL ES and JavaScript as nicely as possible, and there will be plenty of room for the jQuery/Dojo/Prototype/YUI/…. of the world to do nice abstractions on top, but this is good stuff. This is more than just throwing out an API on top of a proprietary system, and I can’t wait to see what comes of it all. Want to get involved? You can in this world.